Evolution Fine-Tuning: Learning to Discover Across 371 Optimization Tasks
A mid-training “practice phase” that turns evolutionary search trajectories into supervision, teaching small open-source LLMs how to evolve solutions before they ever see a new problem.
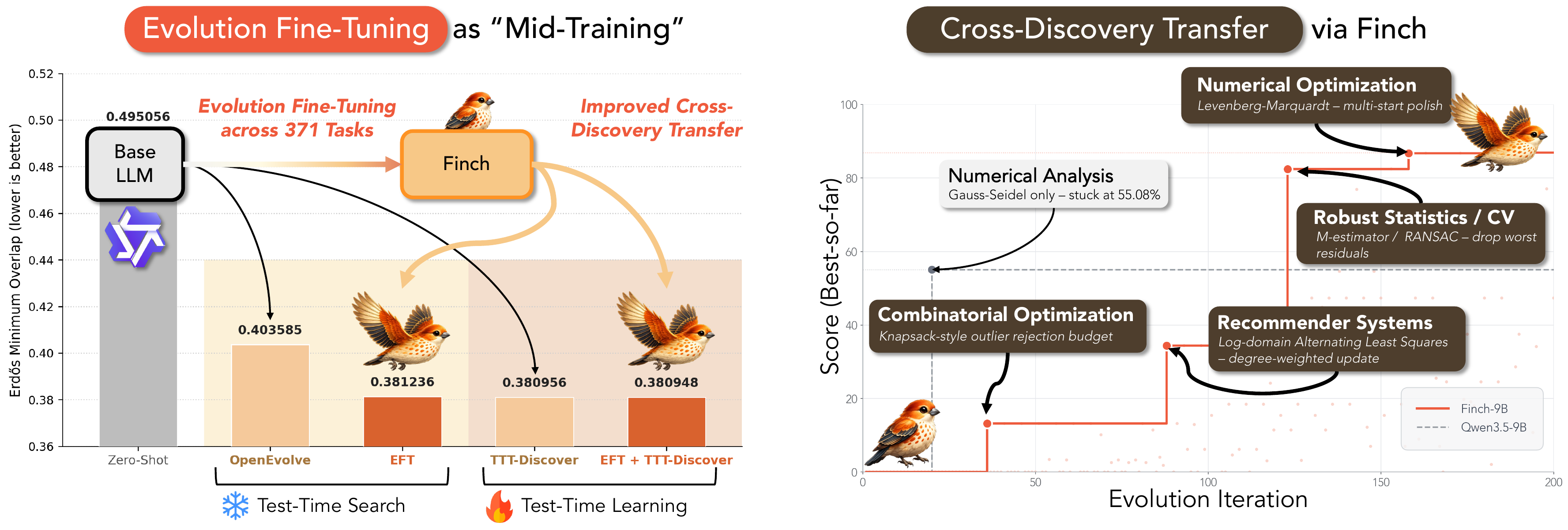
Evolution Fine-Tuning (EFT) converts evolutionary search trajectories into supervision, giving small open-source LLMs a practice phase that teaches them how to evolve solutions before they ever see a new problem. Trained on the 156K-trajectory Finch Collection, our Finch models generalize discovery skill across 22 held-out tasks (+10.22% over base), compose strategies across domains, and reach state-of-the-art on circle-packing when paired with test-time RL.
The problem: discovery skill lives in the scaffold, not the model
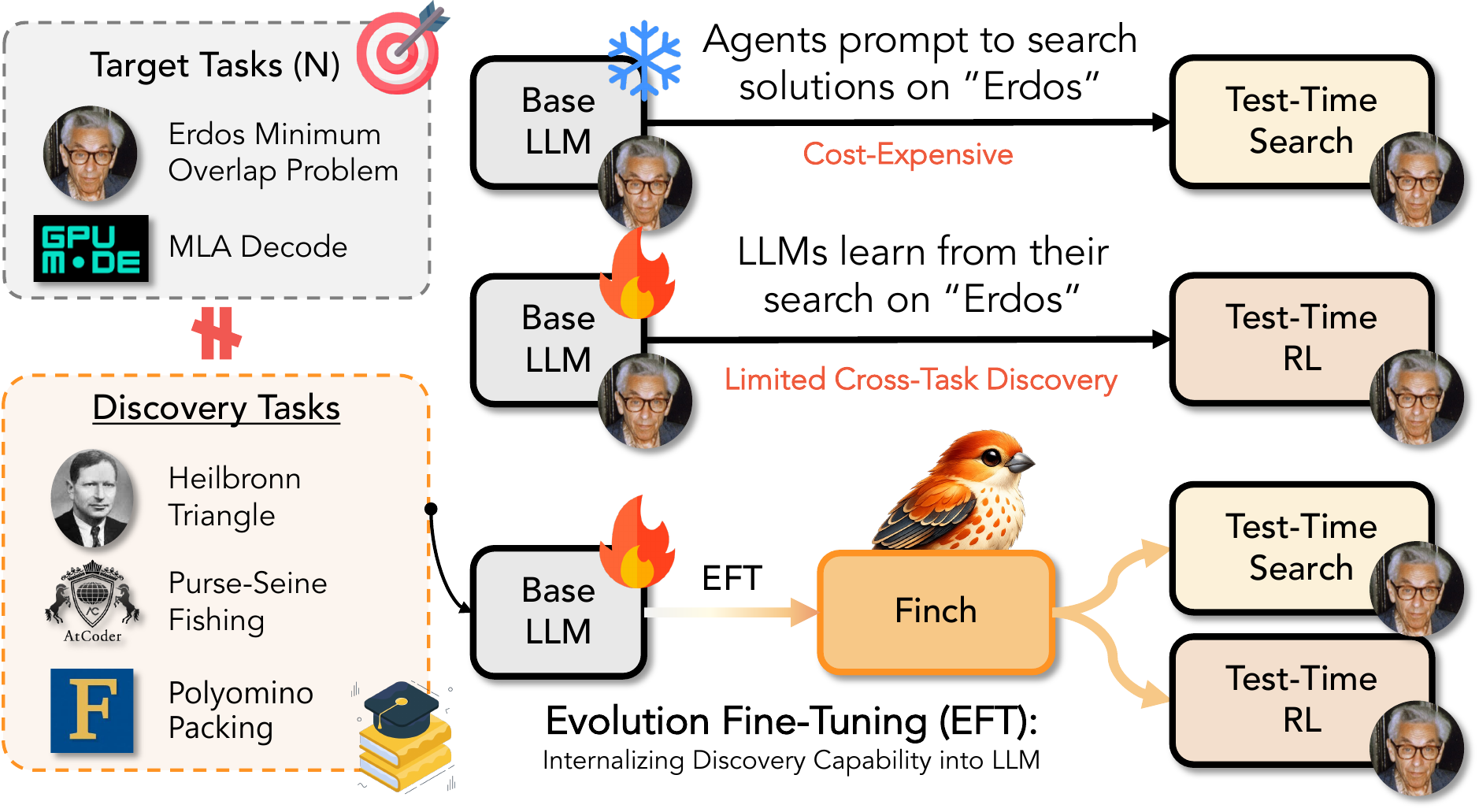
LLMs integrated into evolutionary search have recently produced state-of-the-art solutions on optimization tasks — open mathematical conjectures, GPU kernel design, scientific-law discovery, and combinatorial puzzles. But prior work applies a search scaffold to one target task at a time, so every new problem is approached from scratch and the experience accumulated during search is discarded once the model finishes.
This leaves the capability of iteratively evolving a solution — knowing which part to mutate and how, deciding when to backtrack — entirely in the scaffold rather than in the model itself. Test-time search needs an expensive proprietary mutation operator; test-time learning over-fits a single task and throws the strategy away.
The idea: move discovery skill into the model
EFT is a mid-training paradigm that teaches LLMs to evolve solutions across tasks by distilling the discovery behavior itself into a small model — which then plugs into either scaffold. We think of it as a “practice phase” for general-purpose discovery agents: instead of rebuilding discovery skill from scratch inside every search run, the model practices before deployment rather than solving each new problem from zero.
- A mid-training practice phase — EFT teaches the LLM how to mutate, what to keep, and when to backtrack, before it is ever deployed.
- Trajectories as supervision — optimization tasks are NP-hard and lack ground-truth optima, so (problem, answer) pairs are unavailable. EFT instead treats the trajectories of search runs — parent → child transitions with scores — as the training signal.
- Orthogonal to the scaffold — an EFT model can serve as a frozen mutation operator inside test-time search, or be further adapted by test-time RL. It is a layer beneath both branches, not a replacement for either.
- Emergent cross-domain transfer — trained across many domains at once, Finch composes strategies it learned elsewhere when tackling a new problem, behavior the base model never exhibits.
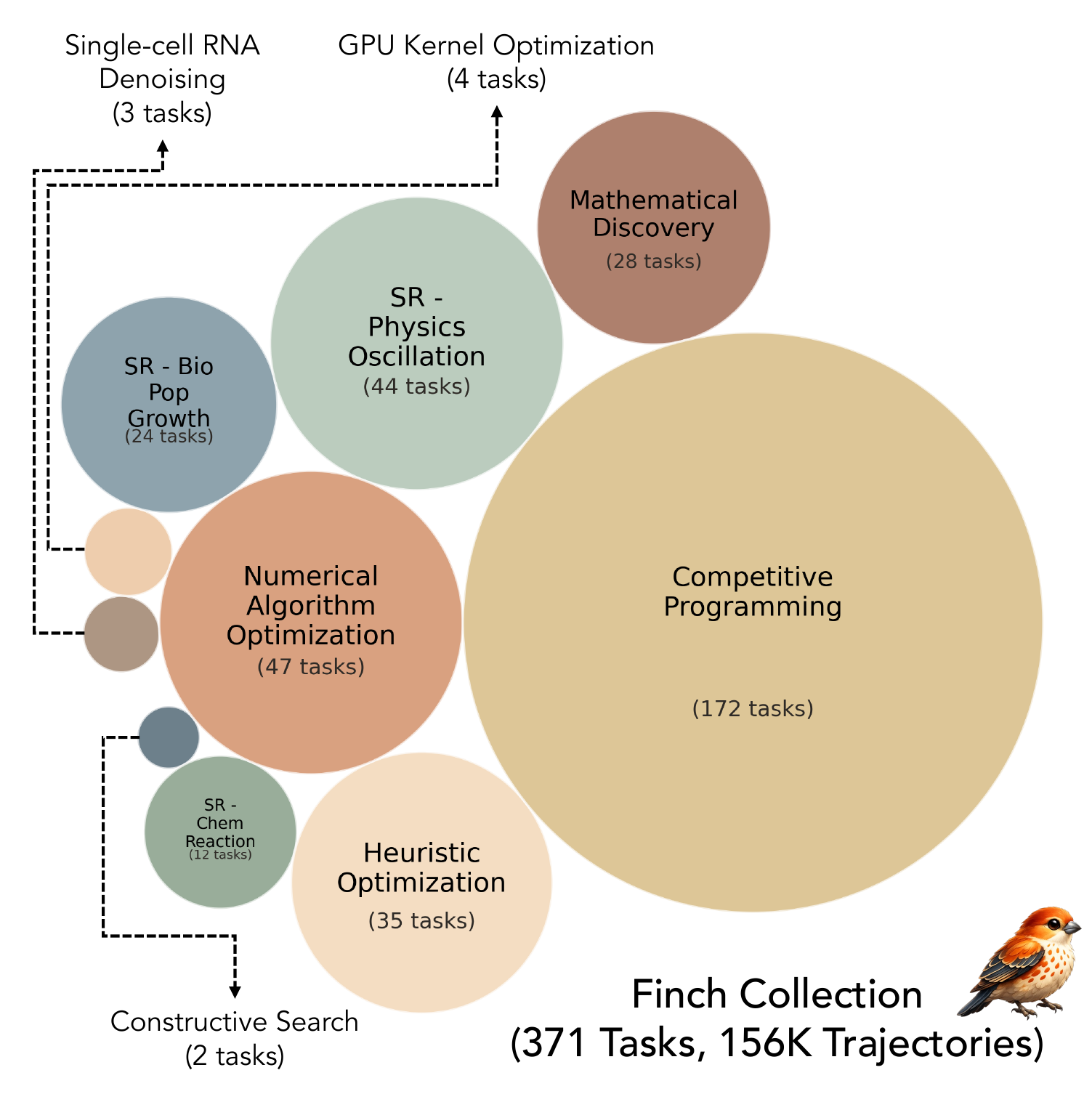
The Finch Collection: 156K trajectories, 371 tasks, 10 domains
Optimization training data is hard to synthesize, so we source 371 seed tasks from 10 existing benchmarks — each requiring nontrivial search, with a deterministic continuous-score evaluator — and harvest the search itself. The construction pipeline runs in three stages:
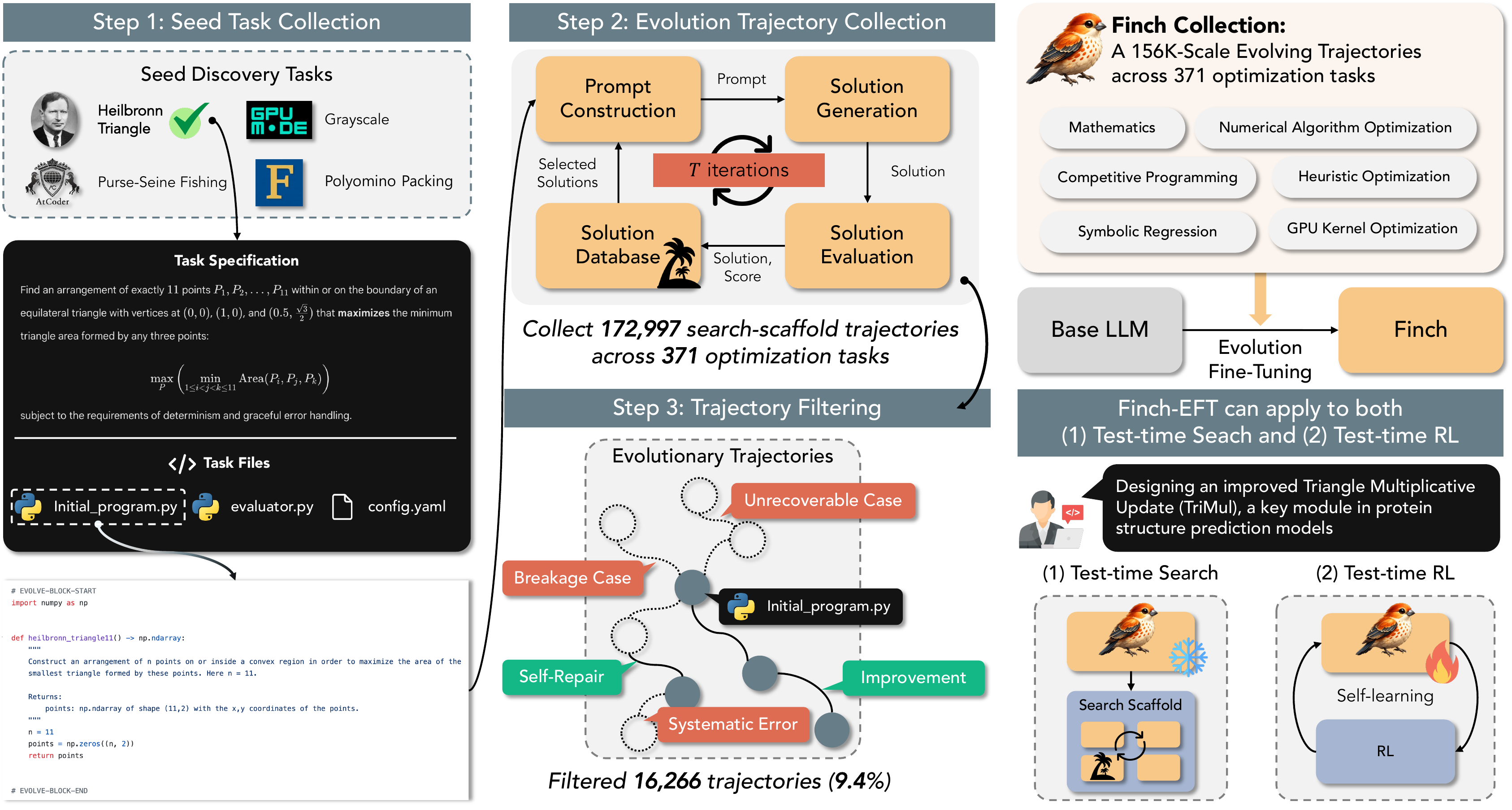
- Seed task collection — 371 tasks across 10 domains, led by competitive programming (172) and numerical algorithm optimization (47), chosen to require real search rather than ground-truth matching.
- Trajectory collection — OpenEvolve with a Qwen3.5-397B-A17B teacher runs each task under diff-edit and full-rewrite strategies, yielding 172,997 raw trajectories.
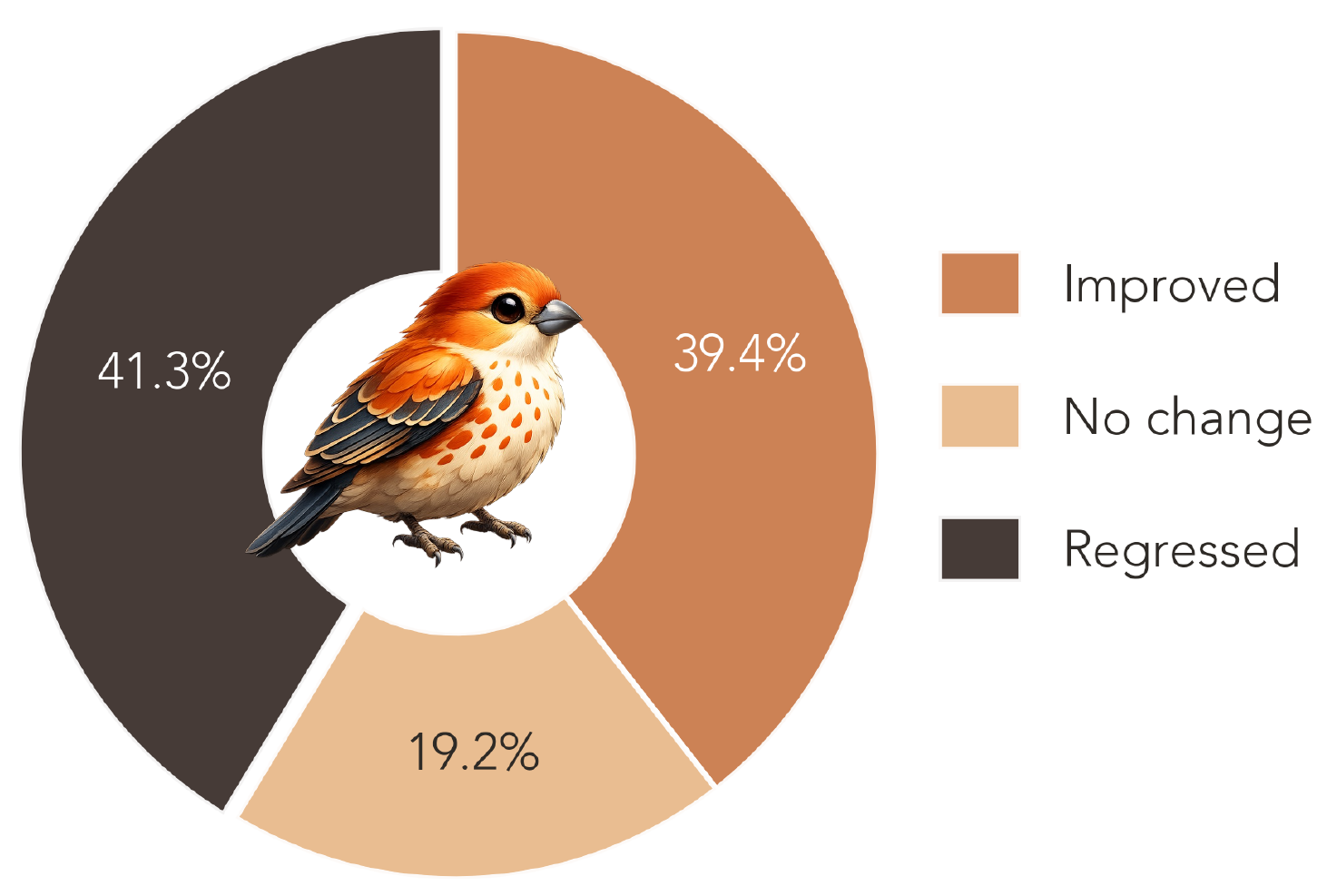
- Filtering & labeling — removing systematic errors, hard-negative breakages, and overlong inputs retains 90.6%, then labels each trajectory by its score delta.
Of the filtered trajectories, 39.4% improve the parent, 19.2% leave it unchanged, and 41.3% regress — supplying both imitation and preference (good-vs-bad) signal. The collection is balanced across languages (68.5% Python / 31.5% C++) and strategies (50.3% diff-edit / 49.7% full-rewrite). We fine-tune the Qwen3.5 (2B/4B/9B) and Qwen3-8B bases via full SFT on improved trajectories from 355 tasks (16 held out), producing the Finch family.
Results: cross-task discovery generalization
Used as a mutation operator inside test-time search, Finch beats its base models across 22 held-out tasks by +10.22% on average — and lets small models rival non-EFT models twice their size. Gains reach +290% on ahc058 and +74% on Transaction, and Finch-4B reaches 0.3865 on the Erdős minimum-overlap problem, comparable to Qwen3-8B's 0.4036 (lower is better) at half the size.
- Test-time search — Finch lifts the held-out average at every scale, up to +10.24% at 9B, and matches strong proprietary operators (Claude-Opus-4.6, Gemini-3-Pro, GPT-5) on several metrics with a far smaller open backbone.
- Offline RL (KTO) — further training Finch on improved + regressed trajectories teaches it to tell good solutions from bad; Finch-8B + KTO surpasses the best human score on two algorithm-engineering metrics.
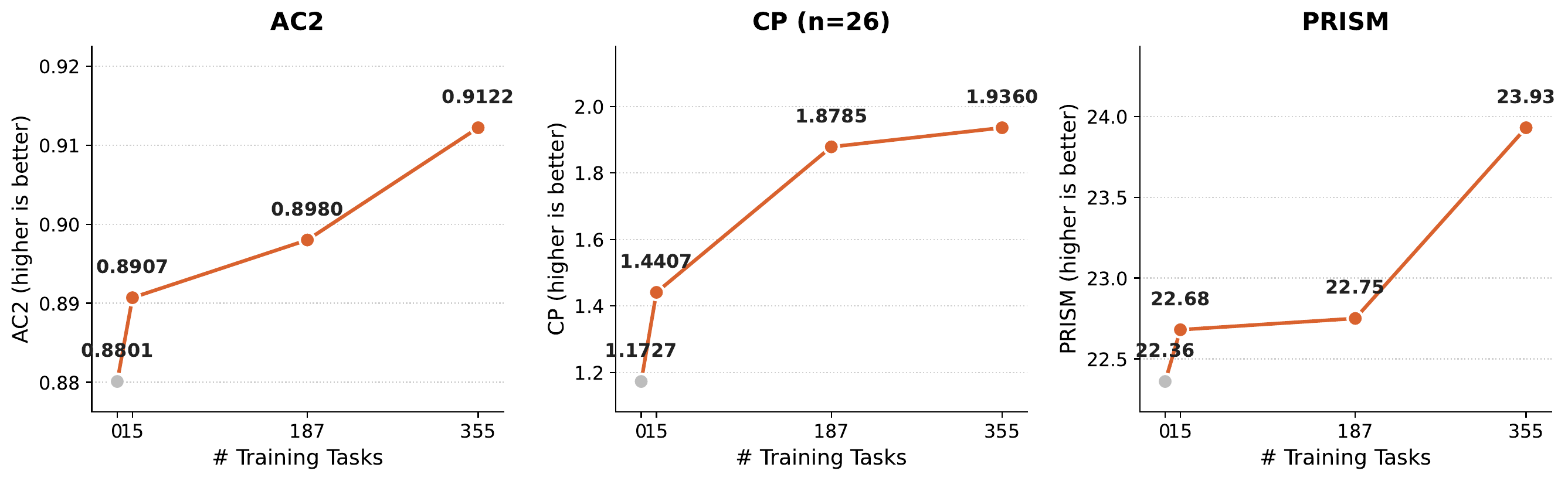
- Online RL (test-time RL) — as the policy inside nanodiscover, Finch-8B matches state-of-the-art on both circle-packing tasks (n=26 & n=32) and edges out the Qwen3-8B base on the Erdős problem.
- Positive task-scaling — as the Finch Collection grows from 15 to 355 training tasks, held-out performance rises monotonically, an average +14.1% improvement that shows the gains come from task diversity rather than any single task.
Why it matters
EFT serves as a practice phase for general-purpose discovery agents that doesn't solve new problems from scratch. By moving discovery skill out of the scaffold and into the model, a single small open-source LLM can plug into test-time search with frozen weights or be further adapted by test-time RL — turning search compute that was once discarded into a reusable, transferable discovery skill. The paper, code, the Finch Collection dataset, and the Finch model family are all publicly available.